C/C++ 内置数据类型
Posted on 2014-03-31 13:37 in CS
类型是程序设计的基础。一些程序设计语言,比如 Smalltalk 和 Python,在运行的时候才检查预计中的对象的类型,相反 C++ 是静态类型(statically typed)语言,在编译时执行类型检查。导致的结果是:
变量和函数在使用前必须先声明。
每种类型都定义了其存储空间要求和可以在该类型的所有对象上执行的操作。C++ 是 在 C 的基础上扩充得到的,为了和 C 兼容, C++ 在必要时必须能够直接处理硬件,所以 C++ 提供的一组基本内置类型,如 int、char 等,这些类型与它们在机器硬件上的标示方式紧密相关,所以 C++ 可以称为 “ 具有高级语言库的低级语言 ”。
本文只限于总结 C++ 的内置类型(Built-in Types),不讨论自定义类型。
基本内置类型
算术类型
C++ 语言自身定义了一组基本类型来表示不同的数据,如整数、浮点数、字母、bool 类型等,这些类型统称为 算术类型(Arithmetic type) 。
size
算术类型的存储空间依机器而定,即用多少二进制位 bit 来表示一个数 。C++ 标准规定了每个算术类型的最小存储空间,但它并不阻止编译器使用更大的存储空间 。事实上,对于 int 类型,几乎所有的编译器使用的存储空间都比所要求的大 。
使用 sizeof() 操作符可以查询对象或类型的大小(以字节为单位),包含头文件
1 | |
就可以使用 STL 库中的 numeric-limits<T>::max 和 numeric-limits<T>::min 查询各个内置内类类型的最大值和最小值。
下面是 Ubuntu amd64 版本上的结果:
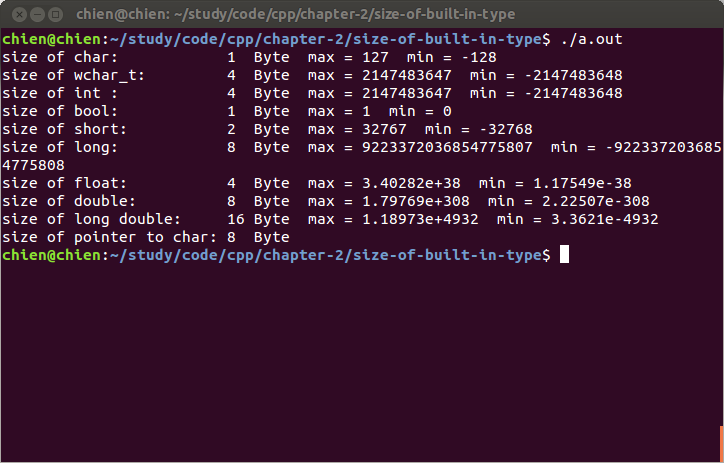
算术类型可以分为两类:表示整数的 整型 和表示浮点数的 浮点型。
Integral Types
表示整数、字符、布尔值的算术类型合称为 整型(integral types)。
整数的基本表示类型是 int 。int 类型前面可以加两类修饰说明,表示数据位数长短的 short 和 long ;表示有无符号的 signed 和 unsigned 。组合出来的结果就有 4 种:
1 2 3 4 | |
每一种的数据长短和可以表示的范围都不相同。
字符类型有两种:char 和 wchar-t 。char 用来表示基本字符集中的字符,wchar-t 用于扩展字符集 ,比如汉字和日语。修饰 int 类型有无符号的 signed 和 unsigned 也可以修饰 char 类型。
C++ Primer (chapter 2) 中写到:
Unlike the other integral types, there are three distinct types for char: plain char, signed char, and unsigned char. Although there are three distinct types, there are only two ways a char can be represented. The char type is respresented using either the signed char or unsigned char version. Which representation is used for char varies by compiler.
为什么会有这么奇怪的事呢?上网搜索了一下,按照自己的理解总结了一下:
signed/unsigned 可以描述的类型有 int 和 char 两种,C 标准里面规定:对于 int 类型,如果没有在类型前显式地声明,默认 int 是 signed 类型,而对于 char 类型,则是 Implementation Defined 。也就是说由编译器在编译的时候决定具体使用哪一种 。而为什么要作出这么奇怪的规定呢?是因为 char 类型本来就是用来表示字符而非数字的, ASCII 码字只使用 7 bit,所以使用 signed/unsigned 对其没有影响,但是如果使用 char 类型来表示一个 8 bit 的数字(有时候空间不够用时不得不这样做,比如嵌入式系统中),为了可移植性,必须写明 signed/unsigned 。所以,如果用来表示字符,则直接使用 char 就行,如果用来表示整数,则声明是 signed/unsigned 。
Linux C 编程一站式学习:整型 中进一步解释:
编译器可以定义 char 型是无符号的,也可以定义 char 型是有符号的,在该编译器所对应的体系结构上哪种实现效率高就可以采用哪种,x86 平台的 gcc 定义 char 型是有符号的。这也是 C 标准的 Rationale 之一: 优先考虑效率,而可移植性尚在其次。 这就要求程序员非常清楚这些规则,如果你要写可移植的代码,就必须清楚哪些写法是不可移植的,应该避免使用。另一方面,写不可移植的代码有时候也是必要的,比如 Linux 内核代码使用了很多只有 gcc 支持的语法特性以得到最佳的执行效率,在写这些代码的时候就没打算用别的编译器编译,也就没考虑可移植性的问题。如果要写不可移植的代码,你也必须清楚代码中的哪些部分是不可移植的,以及为什么要这样写。如果不是为了效率,一般来说就没有理由故意编写不可移植的代码。
网上有博客说:
VC 编译器、x86 上的 GCC 都把 char 定义为 signed char,而 arm-linux-gcc 却把 char 定义为 unsigned char 。
于是,编写一个测试小程序就可以知道我们使用的编译器是如何处理的。
源代码:
1 2 | |
运行结果:
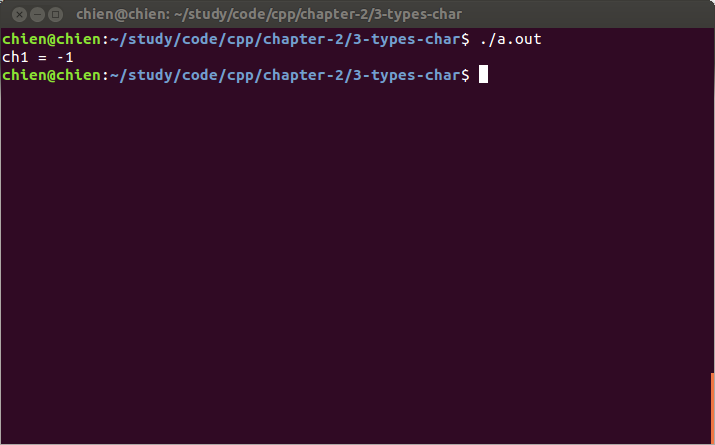
结果说明,gcc 把 char 默认为 signed char 处理。
布尔类型表示 true 和 false 。可以将任何算术类型的值赋给 bool 对象,0 表示 false ,任何非 0 值都表示 true 。
Floating-Point Types
类型 float 表示 单精度浮点数
类型 double 表示 双精度浮点数
类型 long double 表示 扩展精度浮点数
从前面的运行结果可以看出在我的电脑上 float 使用 1 个字(32 bit) 表示,double 使用 2 个字(64 bit) 表示,long double 使用 4 个字(128 bit) 表示 。
C++ Primer (chapter 2):
The float type is usually not precise enough for real programsfloat is guaranteed to offer only 6 significant digits. The double type guarantees at least 10 significant digits, which is sufficient for most calculations.
Determining which floating-point type to use is easier: It is almost always right to use double. The loss of precision implicit in float is significant, whereas the cost of double precision calculations versus single precision is negligible. In fact, on some machines, double precision is faster than single. The precision offered by long double usually is unnecessary and often entails considerable extra run-time cost.
void
void 类型没有对应的值,仅用在有限的一些情况下,通常用作无返回值函数的返回类型。
初始化 Initialize
初始化 & 赋值
首先是初始化的必要性:
在 C++ 中,初始化是一个非常重要的概念,给变量一个初始值几乎总是正确的,但不要求必须这么做。定义变量时,应该给变量赋初始值,除非确定将变量用于其他意图之前会覆盖这个初值。如果不能保证读取变量前重置变量,就应该初始化变量。变量没有初始化是很常见的导致程序崩溃 / 结果错误的原因,而且有时候很难像 Debug 一样找到这个错误(bug 导致程序一定不对,但是没有初始化的变量的结果是随机的)。所以,良好的习惯是对每个变量都进行初始化 。
其次是初始化和赋值的区别:
- 初始化
Initialization:创建变量并且给它赋初始值 - 赋值
Assigment:擦除变量的当前值并用新值代替
C++ 提供两种初始化变量的方法:复制初始化(copy-initialization)和直接初始化(direct-initialization)。复制初始化使用 =,直接初始化使用 () 。
1 2 | |
使用 = 很容易让人把初始化和赋值混淆在一起,但是在 C++ 中这是两种不同的操作,当涉及到类对象时,两种不同的初始化方式的区别是很微妙的。目前先不考虑这点,只需要知道直接初始化语法更灵活而且效率高。
内置类型初始化
当我们定义一个变量却没有初始化时,系统 有可能 会为我们进行隐式的初始化。至于系统是否帮我们隐式初始化变量,以及为变量赋予一个怎样的初始值,这要取决于该变量的类型以及我们在何处定义的该变量。
内置类型的变量是否自动初始化取决于变量定义的位置。在函数体外(全局范围)定义的变量都初始化为 0,函数体内定义的变量不进行自动初始化。
算术类型转换
隐式类型转换
当两个操作数类型不同时,C++ 并不是直接把两个数加在一起,而是提供了一组转换规则,以便在执行算术操作之前,将两个数转换为同一数据类型。这些转换规则由编译器自动执行,不需要程序员介入,有时甚至不需要程序员了解。因此它们被称为隐式类型转换 (implicit type conversion) 。
在以下情况会发生隐式类型转换:
-
混合类型表达式,操作数被转换为相同类型
1 2 3
int ival; double dval; ival >= dval; // ival converted to double -
用作条件表达式被转化为 bool 型
1 2 3
int ival; if (ival) // ival converted to bool while ( cin) // cin converted to bool -
用表达式初始化(赋值)某一变量,表达式被转化为该变量类型
1 2 3
int ival = 3.14; // 3.14 converted to int int *ip; ip = 0; // the int 0 converted to a null pointer of type int *
另外,函数调用时也可能发生隐式类型转化。
算术类型转换
C++ 语言为内置类型提供了一组转化规则,其中最常用的就是算术转化(arithmetic conversion)。算术转化规则定义了一个 类型转换层次,该层次规定了操作数应该按照什么次序转换为表达式中最宽的数据类型。
有两条通用规则:
-
为了保留精度,如果有必要,数据总是被提升为较宽的类型
-
所有含有小于整形的有序类型的算术表达式在计算之前其类型都会被转换成整型(整型提升 integral promotion)
关于有符号数和无符号数,原则是:
-
不同级数据转换,若较宽的类型可以表示所有较窄的类型的数,则直接将较窄的类型提升为较宽的类型,否则,把两个数都转换为无符号的较宽的类型 。
-
同级数据转换,unsigned int 和 int ,signed 类型会转换为 unsigned 类型 。
unsigned 操作数的转换依赖于机器中整型的相对大小,所以,这类转换依赖于机器。
举个栗子:
-
short 类型 与 int 类型 。在我的机器上,short 类型所占用的宽度为半字(2 Byte),int 类型占用的宽度为 1 个字(4 Byte)。所有的 unsigned short 的值都包含在 int 之中,所以,unsigned short 转换为 int 。
-
下面程序
1 2 3 4
unsigned a = 4; signed b = -20; int c = (a+b > 4) ? 1 : 0; cout << "unsigned int b' = " << unsigned(b) << endl;运行结果为
1 2
unsigned int b' = 4294967276 c = 1因为
b = -2被转化为一个很大的正数b' = 4294967276
references
C++ 之 char , signed char , unsigned char,以及 Integral Promotion