Python 学习笔记 #7 —— Generator 生成器
Posted on 2020-06-01 15:13 in CS
What is Generator
PEP 255 -- Simple Generators 原文链接。
Python 中的 generator 有两类,generator function 和 generator expressions。Genrator Function 实际上是一个工厂函数(factory),使用 lazily 计算方式。其特点就是:遇到 yield 之后,函数后续代码就不再执行,但是也不会退出函数,在下次被调用时会从 yield 之后继续执行。
任意一个 generator 都是一个 iterator,但是反之不一定成立。generator 本质上是一种特殊的更高级的 Iterator,高级的地方在于,不用实现 --iter()-- 和 --next()-- 方法,只需要一个关键字 yield.
Why Generator
因为 list comprehensions 语法非常简洁,所以在实际中使用非常广泛,但是 list comprehensions 存在的一个问题是,它的返回值是一个 list 对象,当数据量比较小的时候,直接用 list comprehensions 没有问题,但是当数据量比较大的时候问题就出现了,list 对象会占用大量的内存空间。很多时候实际上我们并不需要一次性全部把 list 生成好放到内存中,因为我们每次只处理其中的一个元素,如果只是在每次需要对应的元素时才生成它,那么就能节省大量的内存空间了,这就是 generator 出现的原因。
Construct Generator
如何得到一个生成器呢?
Generator Function
使用关键字 yield 可以把一个普通函数转换成 generator。下面是一个产生 Fibonacci 数列的典型例子,
#!python
def fib():
prev, curr = 0, 1
while True:
yield curr
prev, curr = curr, prev + curr
Generator Expression
另外一种得到 generator 的方法是 generator expressions,PEP 289 -- Generator Expressions 原文链接。
顾名思义,generator expressions 就是产生 genrator 的表达式,这个表达式的返回值是一个 generator 对象。
Generator Expression 和 List Comprehension 语法非常相似:
- List Comprehension:
[expr for iter-var in iterable if cond-expr] - Generator Expression:
(expr for iter-var in iterable if cond-expr)
正是因为它们的语法非常相似,所以把代码中已有的 list comprehensions 改成 generator comprehensions 非常容易。
list comprehensions 的出现极大地降低了 filter() 和 map() 的使用,同样 generator expressions 的出现极大地降低了 itertools.ifilter() 和 itertools.imap() 的使用,而且 itertools 中的其他迭代器还能和 generator comprehensions 配合起来使用。
Reduction 函数(比如 sum(), min(), max() 等)会把一个 Iterable 对象转换成一个单独的值,这种场景非常适合配合使用 generator。
虽然经过优化之后,在中、小数据量的时候,list comprehensions 和 generator expressions 的性能是差不多的,但是对于大数据量的场景,generator expressions 仍然具有性能优势。
Using Generator
因为 generator 本身是一个可迭代对象 Iterable,所以我们可以直接在 for 循环中使用它,就像迭代 list 对象一样。下面是《python 核心编程》中的一个例子,说明了 generator expressions 的优势和用法。
问题:如何获取一个文件中最大的行长度?
版本一:,打开文件,用 readlines() 把所有的行都读到一个 list 中,然后迭代该 list,找到最大行长度,
#!python
f = open('/etc/motd', 'r')
longest = 0
allLines = f.readlines()
f.close()
for line in allLines:
linelen = len(line.strip())
if linelen > longest:
longest = linelen
return longest
版本二:针对版本一,使用 list comprehensions 简化代码,
#!python
f = open('/etc/motd', 'r')
longest = 0
allLines = [x.strip() for x in f.readlines()]
f.close()
for line in allLines:
linelen = len(line.strip())
if linelen > longest:
longest = linelen
return longest
版本一和版本二的问题在于,readlines 会把所有文件内容都读出来,不适用于大文件的情况。因为迭代器是支持文件类型的,所以我们可以用迭代器来替换 readlines。而且我们已经获取到行内容了,可以直接把行长度存下来,而不是行内容。这里的优化有两个:iterator 的使用可以简化代码,直接保存行长度节省内存。版本三的代码如下,
#!python
f = open('/etc/motd', 'r')
longest = 0
allLines = [len(x.strip()) for x in f]
f.close()
return max(allLines)
版本三的代码的问题在于,因为 allLines 本质上还是一个 list,所以虽然使用了迭代器,仍然需要把整个文件都读到内存中。这个时候就该 generator expressions 出场了,用它来代替 list comprehensions,然后把它放到 max 函数里面,就有版本四的代码,
#!python
f = open('/etc/motd', 'r')
longest = max(len(x.strip()) for x in f)
f.close()
return longest
至此,已经不存在占用内存过大的问题了。不过还可以进一步将其简化为一行代码,
#!python
return max(len(x.strip()) for x in open('/etc/motd'))
最终版的代码非常简洁,用 1 行代码高性能地实现了前面 9 行低效代码的功能,同时也不晦涩。
List Comprehension & Iterator & Generator
总结这三种语法,可以深刻体会到 Python 的设计哲学:Simple is better than complex.
这三种语法让我们可以写出更加简洁优美的代码,不需要写繁琐的 for 循环,也不需要定义和维护一堆中间变量,就可以写出 streaming code,而且大数据量场景下 generator 的 memory/CPU 效率也很高。
下面有一张国外作者文章 Iterables vs. Iterators vs. Generators中的图,帮助区分和理解这三个概念。
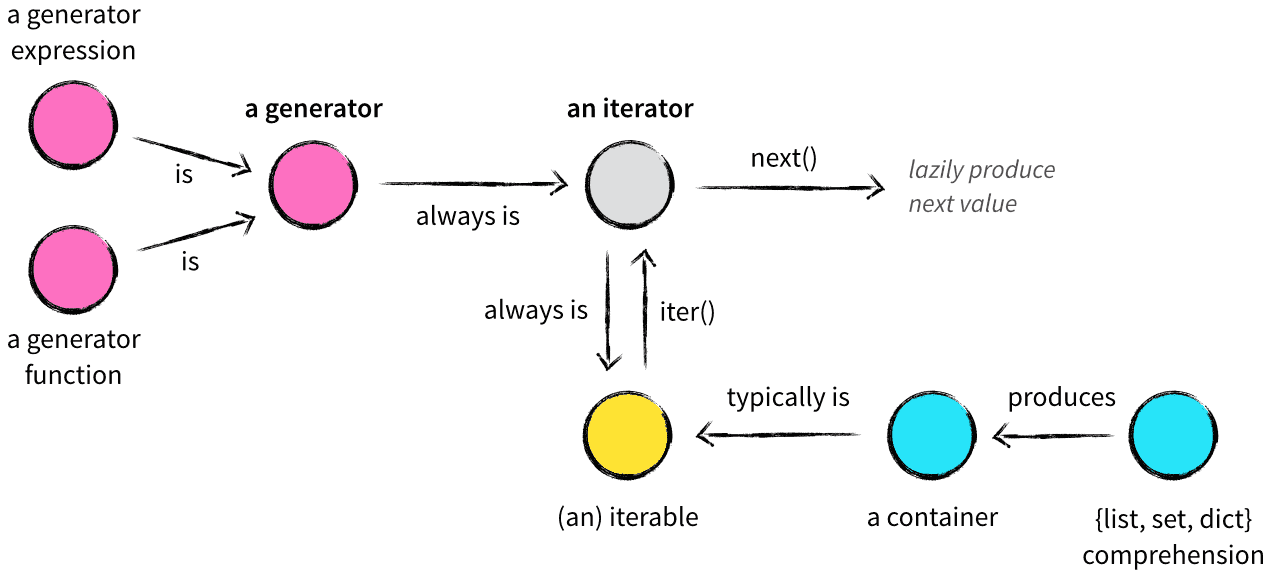
Ref
PEP 255 -- Simple Generators 原文链接
PEP 289 -- Generator Expressions