有限状态机 FSM 设计
Posted on 2014-06-05 17:55 in IC
有限状态机是数字电路中经常出现、非常重要的电路,设计一个安全、高效的状态机有一套程序化的方法,我们在数字电路课中就学习过了。总结一下相关知识,温故而知新~
What is FSM
有限状态机 (Finite State Machine, FSM) 有时候也简称为状态机 (state machine),它是一种数学模型,通常用来设计电脑程序或者时序电路。它被构思设计为一个抽象的机器,并且某个时刻只能处于一个有限数字代表的状态之下。
有限状态自动机在很多不同领域中是重要的,包括电子工程、语言学、计算机科学、哲学、生物学、数学和逻辑学。有限状态机是在自动机理论和计算理论中研究的一类自动机。在计算机科学中,有限状态机被广泛用于建模应用行为、硬件电路系统设计、软件工程,编译器、网络协议、和计算与语言的研究。( 这里讨论的只限于电子工程里的状态机 )
组成元素:输入、状态、状态转移条件、输出
描述方式:
- 状态转移图
- 状态转移表
- HDL 描述
分类:
状态机的框图如下:
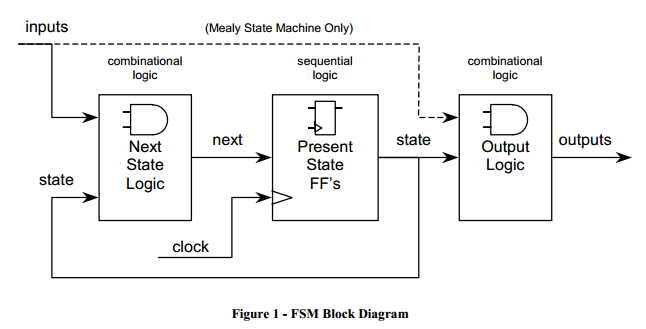
按照输出的产生方式,可以将状态机分为两类:
-
它的输出只取决于当前状态,而与输入无关。Moore 状态机最重要的特点就是将输入与输出信号隔离开来,而且输出与时钟信号同步的。
-
它的输出不仅和当前状态有关,而且和输入也有关。Mealy 有限状态机对输入的响应发生在当前时钟周期,比 Moore 有限状态机对输入信号的响应要早一个周期。因此,输入信号的噪声可能影响在输出的信号。
How to Design a FSM
关于如何设计一个状态机,这在数字电路和逻辑设计的书里有详细介绍。简单地总结一下步骤:
- 逻辑抽象,建立原始状态转移图:确定输入、输出、状态变量、画状态转移图
- 状态简化,得到最简的状态转移图 ( 卡诺图 )
- 状态分配,选择编码方案 (Binary、Gray、One-Hot)
- 画逻辑图,检查能否自启动,得到了最终的状态机模型
How to implement a FSM
当设计好之后,就要使用 HDL 语言来实现这个 FSM 了。
语言: Verilog HDL
综合工具: XST (Xilinx Synthesis Tools)
Coding goals
我们的代码需要达到的目的应该是:
The FSM coding style should be easily modified to change state encodings and FSM styles
The coding style should be compact
The coding style should be easy to code and understand
The coding style should facilitate debugging
The coding style should yield efficient synthesis results
Template
为了达到目的,总结出了下面的这个三段式的模板(使用 index one-hot + reverse case + synopsys FSM 语法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | |
需要注意的是 synopsys FSM 的语法:
-
parameter 定义的两端都要定义位宽,不能省略
-
注释
// synopsys ...的位置不能随意改变
即使改用其他的综合工具,前面的 FSM 定义的综合指令不影响,需要修改的只有 case 综合指令(如 XST 改为 // synthesis full-case parallel-case)。
下面逐个讨论为什么这么写,以及需要注意的问题。
Always Block
状态机一般有三种写法,他们在速度、面积、代码可维护性等各个方面互有优劣。
一段式: 只有一个 always block,把所有的逻辑(输入、输出、状态)都在一个 always block 中实现
-
优点:看起来很简洁
-
缺点:不利于维护,如果状态复杂一些就很容易出错。
不推荐这种方法,但是在简单的状态机可以使用。
二段式: 有两个 always block,把时序逻辑和组合逻辑分隔开来。时序逻辑里进行当前状态和下一状态的切换,组合逻辑实现各个输入、输出以及状态判断。
-
优点:便于阅读、理解、维护,而且利于综合器优化代码,利于用户添加合适的时序约束条件,利于布局布线器实现设计
-
缺点:输出是组合逻辑,可能含有毛刺
解决输出毛刺的问题,最简单的方法就是用寄存器打一拍,但很多情况不允许插入寄存器节拍,此时使用三段式描述。其优势在于能够根据状态转移规律,在上一状态根据输入条件判断出当前状态的输出,从而不需要额外插入时钟节拍。
三段式: 有三个 always block,一个时序逻辑采用同步时序的方式描述状态转移,一个采用组合逻辑的方式判断状态转移条件、描述状态转移规律,第三个模块使用同步时序的方式描述每个状态的输出。这 3 个 always block 正好对应图示的 3 个子模块,更加容易理解。
-
优点:代码容易维护,时序逻辑的输出解决了两段式组合逻辑的毛刺问题
-
缺点: 代码量大、资源消耗多一些
一段 or 三段?
一般来说,三段式的效果更好,唯一的缺点是占用的资源稍微多一点 ( 对于拥有丰富的触发器资源的 FPGA 来说,这个缺点可以忽略吧 )。所以除非是非常简单的状态机用一段式实现,其他情况下三段式更简单。
localparam
尽量使用 localparam 而不是 define 和 parameter。这个原则不仅仅限于 FSM,其他模块也应该遵守。
Reason
-
不使用
define:在设计中很可能有多个 FSM,而且它们很可能包含有相同的状态名,使用define定义的状态名是全局可见的,那么这些 FSM 之间会相互影响(C++ 解决这个问题的方法是 namespace) -
不使用
parameter:虽然parameter定义的参数是局部的,但是它可以被其他模块通过参数修改。FSM 中的状态定义应该是内部可见的,外部模块应该是不能修改的(类似于 C++ 中 class 的 private 成员)。
综上,使用 localparam 是更好的选择。
Reset
FPGA 上电时,GSR(Global Set/Reset) 拉高,对所有 寄存器 /RAM 进行复位,此时配置于 FPGA 的逻辑并未生效,所以不能保证 FSM 进入正确的初始化状态。
解决方法:
-
一般,FSM 使用用户定义的复位 ( 同步 or 异步 )。
1 2 3 4 5 6 7 8 9
// Synchronous Reset always @(posedge clk) begin if (rst) begin CS <= IDLE; end else begin CS <= NS; end end -
还有一种方法,是将初始状态编码为全 0 ( 带 0 的 One-Hot 编码方式 ),这样当 GSR 复位后,状态机自动进入初始状态。
State encode
状态机的状态的编码,通常有 Binary、One-Hot、Gray 码等几种。
Binary 码
采用最简单的递增的编码方式对状态进行编码,对于 n 个状态的状态机,共需要 log2(n) 个触发器表示所有的状态。
-
优点:在状态很多的情况下,可以大大减少触发器的数量,对设计的面积有积极的作用。
-
缺点:但是在状态跳转过程中,很可能出现多位同时变化的情况,容易在 next state 的生成逻辑上产生毛刺。同时,输出也是所有状态位的译码,译码逻辑多数很复杂,往往成为整个设计的关键路径。
Gray 码
类似 Binary,但是采用了格雷码的编码方式,每两个相邻的状态只有一位信号变化。
-
优点:避免了 next state 上毛刺的产生。同时两个相邻状态的输出译码变得简单了,避免了复杂组合逻辑的产生。
-
缺点;格雷码的这些优点都是建立在状态跳转是顺序执行的基础上的。如果状态机有很多随机跳转和分支,格雷码的实际效果和二进制码相差无几,优势荡然无存。
One-Hot 码
当前设计中最常用的状态机编码方式。One-Hot 编码在一组 0 中只有一个 1,对一个 n 个状态的 FSM 设计,需要 n 个触发器。
-
优点:在任意两个状态之间跳转都只有两位状态位变化,不会产生非常复杂的组合逻辑。各个状态之间的译码也相对简单。
-
缺点:对状态编码需要的寄存器比其他方式多,不过这个缺点基本可以忽略吧 :-P
结论:
Binary、Gray 编码使用最少的触发器,较多的组合逻辑。而 One-Hot 编码反之。由于 CPLD 更多的提供组合逻辑资源,而 FPGA 更多的提供触发器资源,所以 CPLD 多使用 Gray,而 FPGA 多使用 One-Hot 编码。另一方面,对于小型设计使用 Gray 和 Binary 编码更有效,而大型状态机使用 One-Hot 更高效。
(XST 的选项 FSM encoding algorithm 值默认为 auto,编写程序测试发现,它会根据代码中状态的多少,FSM 的复杂度,自动选择合适的编码方式对状态进行编码。)
Note
one-hot 和 reverse case 相结合,可以得到一种更加简洁的电路(如模板所示的 index one-hot),这种方式和传统的 one-hot 相比,它不再是对比整个状态向量的值,而是逐 bit 对比,从而简化了状态译码电路。
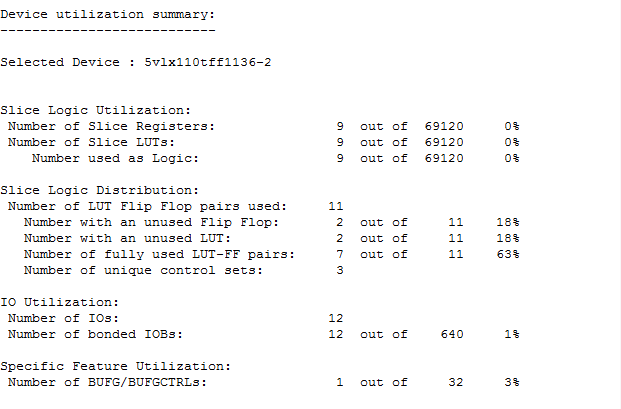
利用前面的模板和结尾附录的模板,对参考文章 Steve Golson State machine design techniques for Verilog and VHDL 中的状态机例子进行综合测试,实际结果证实了 index 方式要更加节省资源(如果状态机更加复杂一些的话,两者的差别应该更大)。
index one-hot style:
non-index one-hot style:
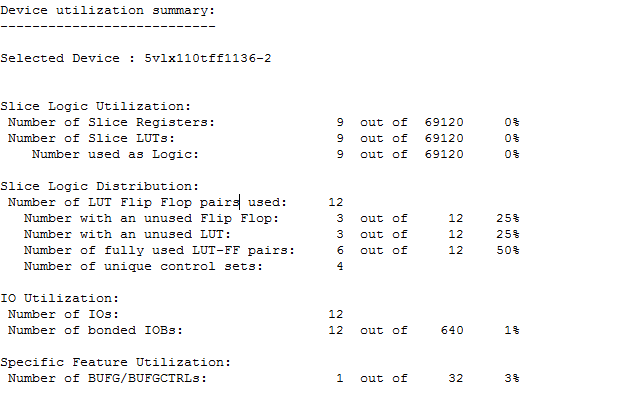
使用 XST 综合上面的 index one-hot + reverse case 风格的 FSM,结果 XST 并没有识别出 FSM,而 Synplify 我没有破解版本,只能作罢 =.=
虽然 XST 没有识别出 non-index 的 FSM,但是 Modelsim 是可以识别出来的,可以在 Modelsim 中查看最终综合出来的 FSM 如下:
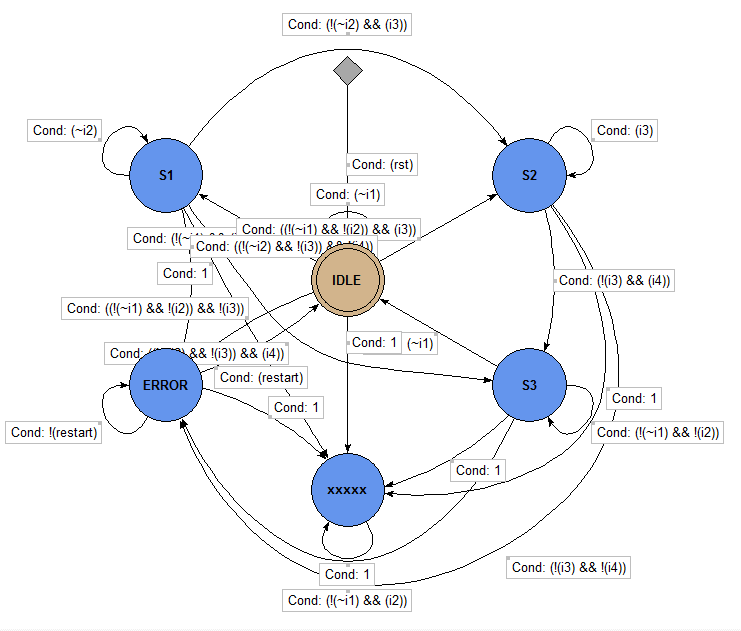
补上普通的 one-hot + case 的模板,这个模板是可以被 XST 识别出来的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | |
Safe FSM
所谓 “ 安全 ” 的状态机,就是说即使因为某些意外原因,状态机跑飞了,仍然可以自动回复到正常状态。
举例:可能出现的不安全情况
比如,我们采用 One-Hot 编码方式,对于 8 个状态,总共使用了 8 bit 的寄存器,那么这个状态寄存器向量可以取到的值一共有 2^8 = 256 种。如果我们只对需要的 8 种状态进行了说明,而忽略了剩余的 248 种,此时综合工具 (Synplify、XST) 会对设计进行 “ 优化 ”,将没有用到的状态去掉。但是,有时候这种 “ 优化 ” 反而不好,如果状态机进入未定义的全 0 状态,那么它就会卡在这个未定义的状态,无法自动回复正常工作状态。
解决方法
有两种方法:
-
如果我们对状态向量的所有取值情况都显式地进行了说明,那么这个状态机就是安全的,否则就是不安全的。书写完备的
case语句。在代码中对每一种可能的取值对进行描述,对于不使用的状态编码,一定要有default分支进行说明。在第二段
always中,1 2 3
default: begian NS = IDLE; end这里应该赋值
8'bx更合理,因为状态机上电时处于未知状态,所以应该赋值x更符合实际,但是这样赋值必须有个条件,就是必须所有的状态编码都全部被使用了,不然就会出现锁死现象,FSM 无法返回工作状态。我们前面使用的是 One-Hot 编码方式,有大量无效状态,所以这里不能赋值为x。 -
XST 支持状态机编码的完备属性 ——
case implementation style但是这个设置可能会导致前后仿真不一致的问题,一般不使用。我们应该在代码中满足条件,而不是依靠综合工具。
XST 的选项
safe implementation值默认为None,如果应用环境要求 FSM 必须能恢复任何错误,比如航天、医疗、汽车等,这时我们可以打开这个设置,这时综合工具会添加额外的逻辑,保证 FSM 可以从无效状态恢复过来。
即使使用第一种方法,似乎我们的状态机已经是 perfect 了,但是真的是这样么?考虑这种情况:一个状态机有 8 个状态,采用 One-Hot 编码方式,代码含有 default 分支处理未定义的状态向量可能取到的值。现在把这个状态机放在卫星中,接受宇宙射线的辐射,导致状态向量的值发生了变化,进入了无效状态,然后状态机自动恢复到正常状态 (Good Job),但是!状态机的外围电路并没有随着状态机恢复,它还在等 FSM 输出某个信号呢。
所以,仅仅是回到正常状态并不够,最好的设计应该有个错误状态专门来与外围电路通信,当 FSM 进入错误状态时,外围电路会检测到这个错误状态,并采取合适的措施(如重启、复位 FSM)。
结合上面讨论的 index one-hot 编码方式,就有了两种方案:
-
显式地定义定义一个 ERROR state
如模板所示。
比如一个 FSM,有 4 个状态,分别是 IDLE、S1、S2、S3,那么额外定义一个 ERROR 状态机的框图如下:
1 2 3 4 5
parameter [4:0] IDLE = 5'd0, S1 = 5'd1, S2 = 5'd2, S3 = 5'd3, ERROR = 5'd4;在每个 case item 中,最后添加一个 else 分支且
NS[ERROR] = 1'b1,并且多加一个 case item1 2 3
CS[ERROR]: begin if (restart) NS[IDLE] = 1'b1; end -
zero-idle
在状态定义时,不用显式地定义一个 ERROR 状态,而是用全 0 状态表示 ERROR 状态:
1 2 3 4
parameter [4:1] IDLE = 5'd1, S1 = 5'd2, S2 = 5'd3, S3 = 5'd4;多加一个 case item:
1 2 3
~|CS: begin if(restart) NS[IDLE] = 1'b1; end
对比两种方式,我觉得第一种更能体现出设计意图,所以在模板中选择这种方式。
case(CS)
使用 case 的原则: 尽量不要使用综合指令 full-case 和 parallel-case,而是代码本身满足 full、parallel 的条件(因为综合指令可能导致前后仿真不一致的问题)
下面根据状态编码方案分类讨论:
-
如果使用 “ 非 index one-hot + 非 reverse case” 的方法,那么在第二个 always block 中,在 case 前给 NS 一个默认值(如下)
1NS = 8'bx;这是个很有用的小技巧,它可以帮助我们在综合前发现状态是否完备:如果状态完备,则在下面的
case中会给NS合适的值;如果状态不完备,则状态机会进入错误状态,输出不定,仿真时可以很快的发现。而且,综合工具对于x采取的态度是don't care,综合时会自动将其忽略,生成的电路最简洁。 -
如果使用 index one-hot + reverse case 的方式:
-
NS 必须赋值为全 0:
1NS = 8'b0; -
使用 synopsys 综合指令
一般的原则是尽量不要使用综合指令,这里是个特殊情况。
1// synopsys full-case parallel-case -
default 分支
使用了综合指令,则 default 分支在综合时就没有必要,但是仿真器并不能识别综合指令,所以在行为仿真的时候仍然需要 default 分支,所以可以用下面的方法:
1 2 3
// synopsys translate-off default: $display("FSM is dead!"); // synopsys translate-on
采用 index one-hot + reverse case 的方式,这里违背了 case 语句本身满足 full-case、parallel-case 的原则,使用了综合指令、并且省掉了 default 分支,是唯一的例外情况,其他情况下都应该遵守这一原则!
-
Ouput
避免 Latch
-
在第三个
always中,在case前,所有的输出都有默认的值,这样做的好处是可以消除Latch的出现,而且,可以减少在后面每种状态下重复相同的赋值,而且强调显示了 case 内哪个输出发生了变化。 -
另外一种避免 latch 的方法:书写完备的
if-else和case语句。
消除输出毛刺
对于三段式,因为输出是寄存器输出,所以解决了输出毛次。
讨论一下采用寄存器输出的方式对设计的影响
-
输出采用寄存器驱动可以优化 FSM 的时序性能
影响一个时序电路运行速度的主要因素是两个寄存器之间的组合逻辑路径的长度,越长的组合逻辑路径,其时序性能越差。一个电路中的最长组合逻辑路径决定了这个电路最高运行速率,该路径就是这个电路的关键路径(
critical path)。所以,切断最长的组合逻辑路径可以提高局部电路的运行速度,切断多个较长的组合逻辑路径可以提高整体电路的运行速度。切断组合逻辑路径的工具就是寄存器。所以,添加寄存器可以提高电路的性能,但是会增加资源的消耗,这也是速度(speed)和面积(area)互为矛盾的原因。在考虑 FSM 的时序问题时,不能独立的考虑 FSM 本身,需要综合考虑 FSM 模块和下游模块构成的电路。在 FSM 不采用输出寄存时,在 FSM 模块和下游模块的接口处,是两部分组合逻辑直接相连。关键路径由两部分组合逻辑构成;在 FSM 采用输出寄存时,两个模块的组合逻辑被分隔成两部分,可能的关键路径被切断了。同步寄存器输出和组合逻辑输出就是采用资源优化还是速度优化的问题。组合逻辑表面上会提高电路的速度,看似节省了资源而且提高了速度,其实不然(对 FPGA 结构来说,节省寄存器不等于节省 LE;对同步设计来说,异步输出速度上的优势是可以忽略的)。
-
输出采用寄存器驱动会降低输出队输入信号变化的响应速度?
到底应不应该采用 FSM 输出寄存器?是否必须在时序性能和响应速度之间做出取舍?在同步设计中,答案是必须牺牲一定的响应速度以换取更佳的时序性能,只考虑响应速度会带来潜在的时序性能损失。
在考虑 FSM 的响应速度时,不能独立的考虑 FSM 本身,需要综合考虑 FSM 模块和上、下游模块构成的电路。采用输出寄存器的电路可以运行在更高的时钟频率下,所引入的响应时延与更高的运行频率相比是可以牺牲的。
case (NS) vs case (CS)
采用二段式实现状态机,它的输出是组合逻辑,可能存在竞争和冒险,产生毛刺,要消除毛刺就要对输出用寄存器打一拍,但是很多时候,是不允许插入寄存器节拍的。
这时候可以采用三段式实现,三段式的输出是寄存器输出,所以消除了毛次;同时,如果三段式的第三段判断输出采用
1 2 3 4 5 6 7 8 9 | |
就可以提前判断下一状态的输出,节省了一个节拍,使输出和状态变化同步。
example
设计一个简单的 FSM,测试使用 case(CS) 和 case(NS) 的结果:
FSM 设计:一共有 4 个状态 (IDLE、S1、S2、S3),只有一个输入 (jump 信号 ),两个输出 (dout-p、dout-q)。
跳转规律:状态机开始处于 IDLE 状态,当 jump 变高时,从 IDLE 跳转到 S1 状态,同时内部的一个 4 bit 计数器开始计数,当计数到 4'b1111 时,跳转到 S2,当再次计数到 4'b1111 时跳转到 S3,当再次计数到 4'b1111 时,跳转到 IDLE,等待 jump 再次变高。状态转移图:
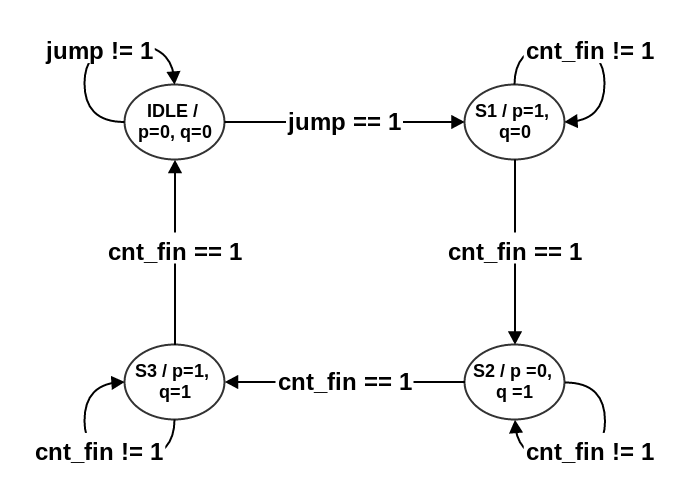
程序:
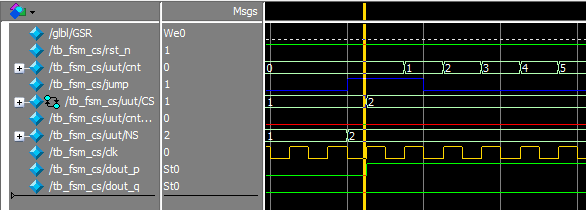
仿真结果:使用 NS 判断,结果如下图,可以看到,当 CS 发生变化时,输出同时改变。
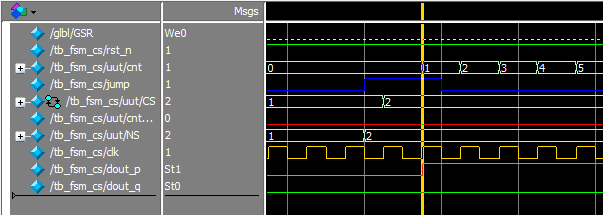
使用 CS 判断,结果如下图,可以看到,当 CS 发生变化时,输出变化相对于状态变化延时一个时钟周期。
Ref
Clifford E. Cumming State Machine Coding Styles for Synthesis
Steve Golson State machine design techniques for Verilog and VHDL
foreveryoung 《状态机设计》
云创工作室《 Verilog HDL 程序设计与实践》